Java异常处理
Contents
💠
-
- 1.1. 异常的继承关系
- 1.2. 常见异常
- 1.3. 最佳实践
- 1.3.1. 异常被吞问题
- 1.3.2. 不填充异常栈
- 1.3.3. 异常栈被隐藏
- 1.3.4. 应该使用大块的try还是细颗粒度的try?
- 1.3.5. try和for谁包住谁更好?
💠 2025-02-08 15:22:46
异常
相关博客:Java异常浅谈
异常的继承关系
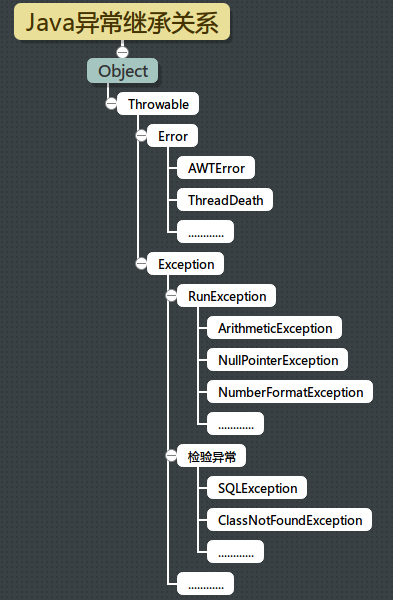
Java将所有非正常情况分为两种 异常(Exception)和错误(Error) 它们都继承Throwable父类。
Error一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,动态链接失败等,这种错误无法恢复或不可能捕获,将导致应用程序中断,通常应用程序无法处理这些错误;
因此应用程序通常不应该使用catch块来捕获Error对象,在定义方法时也无须在其throws子句中声明该方法可能抛出Error及任何子类。
非受检异常: 继承于RunTimeException或Error. 其他的都属于受检异常
常见异常
常发生于集合并发修改和迭代时 ConcurrentModificationException
常发生依赖版本冲突 ClassNotFound NoSuchMethodException 等等
最佳实践
异常被吞问题
- catch 代码块中出现异常 会导致栈中看不到try块中的异常
- 线程池提交的任务未catch,异常溢出到线程内,未处理妥善会吞异常信息
不填充异常栈
捕获栈帧填充错误信息是靠 fillInStackTrace 实现,手动重写为空实现就可以降低异常创建时的成本,可用于业务型,原因明确的异常 做业务的中断以及告警等场景。
|
|
异常栈被隐藏
在使用服务器模式下,会默认开启 Fast Throw 机制, 以下异常被频繁抛出时(大于5000),会隐藏错误栈
- NullPointerException
- ArithmeticException
- ArrayIndexOutOfBoundsException
- ArrayStoreException
- ClassCastException
JVM参数关闭该特性 -XX:-OmitStackTraceInFastThrow
应该使用大块的try还是细颗粒度的try?
为了避免我们遗漏掉一些可能会出现异常的代码, 所以建议使用大块的try, 因为检查型异常是容易发现的, 但是运行时异常却往往不能在编码的第一时间发现
检验异常在开发中如果不进行处理(捕获处理或声明抛出)编译器就会报错不让通过的, 如果平时没有注意异常的系统性学习,
开发就会有这样一种现象: 程序中通篇只有校验异常. 一般这种校验异常默认的处理方式(使用IDE)是颗粒度小的.
但是程序运行出问题的大多是运行时异常, 空指针, 数组越界, 类型不匹配, 除数为0 等等.
使用大try就不会遗漏运行时异常,但是不能仅仅依靠他, 运行时异常还是尽量使用好的编程习惯来规避的.
当然也是可以在大try中使用小try进行开发这样就能对异常进行具体的捕获和处理以及响应
按下葫芦浮起瓢, 关于异常, 可以从另一个角度: 性能方面的维度去考虑:
异常机制的设计初衷是用于不正常的情形, JVM很少对其生成的字节码进行优化, 把尽可能多的代码放在try块中就会阻止了JVM实行原本可以执行的某些特定优化
try和for谁包住谁更好?
具体业务具体分析, 如果要求循环一出问题后续的循环还是要继续执行, 那么就把try写到for中;
如果要求后续的循环不执行就用try包住for
另外: 手动创建线程实现的定时任务在循环处理数据时出现异常必须要及时处理, 否则线程会停止 尽量使用Schduler线程池
异常处理
一般来说, 异常都是层层上抛, 针对 Service Dao Controller 这种结构的设计, 业务异常在Service层手动处理,参数校验则在Controller层统一处理
除非这个异常是无关大局的, 即局部发生对其他模块没有影响, 那么就可以就地捕获不需要上抛
大的try块中 特别处理要看情况抛出, 一般进行封装后, 抛出自定义异常, 上层接收后, 进行二次处理和转化,
直到最外层的调用处, 由最外层调用者决定最终如何处理 只要在使用对象前进行对象的非空判断, 基本就能杜绝空指针异常,
这样的话要引入大量的if块, 如果的确很复杂了可以使用设计模式做优化 例如策略模式,否则不需要
全局异常处理
JavaSE
Java Global Exception Handler
线程默认异常处理
SpringMVC
|
|
源码入口 org.springframework.web.servlet.DispatcherServlet#processDispatchResult
异常和日志的结合
异常一定要和日志结合使用, 日志记录的简约优雅, 维护才越轻松, 日志的存在就是为了解决问题的方便和有迹可循,
所以要记录的任何信息都是为了解决问题, 无关信息就没有必要放进来了(日志存储和解析搜索也是需要成本的)
常见日志格式:时间 线程 类 方法 行数 报错信息
根据业务需要还可以加上 traceId, 用户id, 订单id等等
自定义异常
虽然Java提供了大量的异常类, 但是这些异常类还是难以满足业务开发时的诉求。
通常自定义异常只要继承Exception 重写相关构造器即可.
一般来说自定义异常具有以下类型: 业务异常, 用户异常, 系统异常, 接口异常, 网络异常, 参数异常等等.
根据项目需要, 可以将异常细分, 比如写一个订单保存, 那么针对订单保存的业务可以在不同的代码逻辑里提示不同的异常信息, 接口级异常也是如此,目的是为了将Exception进行封装, 形成易于理解的异常信息.
自定义异常的设计原则
- 用户层面: 用户提示信息优雅
- 系统层面: 让自己维护起来更方便
- 接口层面: 查询问题更直观, 轻松, 为自己留证据, 避免推诿扯皮
- 网络层面: 及时发现问题, 及时进行处理
自定义异常的错误码
正规项目中都会有接口文档, 也会有规范注释, 在项目中也会有一些静态常量
假设定义一个错误码 00X1 表示空指针, 定义要有规律和分类, 方便查询和管理, 通常来说这个错误码不是给客户使用,而是给运营和开发人员快速排查问题。
实现机制
Java 基础 - 异常机制详解
透过JVM看Exception本质
Java异常到底是个啥——一次异常引发的思考
Java 虚拟机:JVM是如何处理异常的?
|
|
查看字节码: javap -v class 或者通过IDEA中插件 jclasslib Bytecode Viewer
|
|
流程:
- 偏移9: new一个RuntimeException对象
- 12: dup 复制上诉对象到栈顶
- 13: invokespecial 调用异常类构造器
- 16: athrow
- 这个指令运作过程大致是首先检查操作栈顶,这时栈顶必须存在一个reference类型的值,并且是java.lang.Throwable的子类(虚拟机规范中要求如果遇到null则当作NPE异常使用)
- 然后暂时先把这个引用出栈,接着搜索本方法的异常表(Exception table)找一下本方法中是否有能处理这个异常的handler
- 如果能找到合适的handler就会重新初始化PC寄存器指针指向此异常handler的第一个指令的偏移地址。接着把当前栈帧的操作栈清空,再把刚刚出栈的引用重新入栈。
- 如果在当前方法中找不到handler,那只好把当前方法的栈帧出栈(这个栈是VM栈,不要和前面的操作栈搞混了,栈帧出栈就意味着当前方法退出)
- 这个方法的调用者的栈帧就自然在这条线程VM栈的栈顶了,然后再对这个新的当前方法再做一次刚才做过的异常handler搜索
- 如果还是找不到,继续把这个栈帧踢掉,这样一直到找
- 要么找到一个能使用的handler,转到这个handler的第一条指令开始继续执行。
- 要么把VM栈的栈帧抛光了都没有找到期望的handler,这样的话这条线程就只好被迫终止、退出了
线程可设置默认handler setDefaultUncaughtExceptionHandler。
Exception table: 异常匹配的表格 如果from 和 to 之间匹配到 type的异常抛出,就转到 target 处执行代码
Author Kuangcp
LastMod 2018-12-13