Java中的HashMap
Contents
💠
💠 2024-04-07 15:54:52
HashMap
参考: 死磕 java集合之HashMap源码分析
Java HashMap工作原理及实现
HashMap 怎么 hash?又如何 map?
参考: Java 8系列之重新认识HashMap
注意: JDK1.8 才引入了红黑树的实现
最坏时间复杂度从O(n)到O(logn), 一定程度上避免了哈希碰撞导致的DOS攻击
结构
HashMap的数据结构是 数组(称为bucket)加单链表 (数组是只放一个Node对象, 单链表是为了放通过hash计算得到的index一致的元素包装成的Node对象)
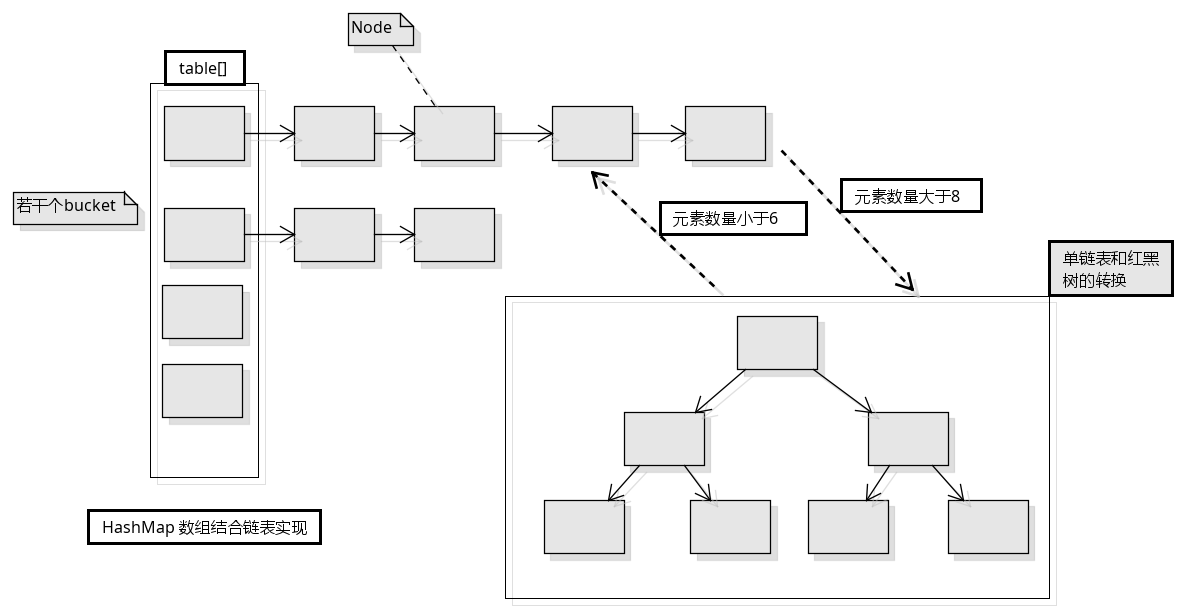

这种设计的好处是, 如果 hash 足够分散, get 时的时间复杂度为 O(1), 反之则是 链表 O(n) 红黑树 O(log n)
构造函数
- 空构造函数: 采用默认初始容量 16 和 默认负载因子 0.75
- 初始容量参数: 采用传入的初始容量, 默认负载因子
- 初始容量, 负载因子参数: 采用传入的两个参数
其中初始容量会根据 tableSizeFor 方法计算得到 大于初始容量的最小的2的指数值 3->4 4->8 …
put
得到 key 的数组下标:
(n - 1) & key 的 hash 值, 其中 n 为数组大小
学习队列的时候有种简单的思路就是直接将 key 的值 对数组大小取余, 就得到了key的正确下标
但是HashMap采用这种设计的优点是性能更好,因为Java中的取余实际上是 a - (a / b) * b
使用与运算会更好, 并且为了数据足够分散, HashMap的数组大小都是2的指数, 是为了数据足够分散
-
计算key的hash值(先计算hashCode 然后进行 高低位做异或运算 (高16和低16做异或)
(h = key.hashCode()) ^ (h >>> 16)); -
if桶(数组)大小为0,则初始化桶; -
if桶中key的下标上没有节点对象,则直接插入; -
else如果有节点对象ifkey的下标上有节点对象 转#流程;else if有节点对象且为树节点,则调用树节点的putTreeVal()插入key对应的节点对象;else则遍历桶对应的链表查找key是否存在于链表中;if找到了对应key的节点,则转#流程;if没找到对应key的节点,则尾插法插入节点 并判断是否需要树化;
-
每当插入新节点,则 ++size 并判断是否需要扩容, 扩容扩的是数组;
#如果找到了对应key的元素,则判断是否需要替换旧值,并直接返回旧值;
putAll
- 可用于复制map内容
resize
- 如果旧容量大于0,则新容量等于旧容量的2倍,但不超过最大容量2的30次方,新扩容阈值为旧扩容阈值的2倍;
- 创建一个新容量的桶;
- 移动元素
if该下标只有一个节点, 就rehash下直接放过去newTab[e.hash & (newCap - 1)] = e;if该下标上是一个树节点 则打散成两棵树((TreeNode<K, V>) e).split(this, newTab, j, oldCap);else也就是说将原链表分化成两个链表,低位链表存储在原来桶的位置,高位链表搬移到原来位置加旧容量偏移的位置上去;- 例如桶的原大小4 , 节点的hash 3、7、11、15
index = ((4-1) & hash) - 扩容一次 3和11保持不变(因为
hash&oldCap == 0), 而 7和15要搬移到(4-1) & hash + oldCap中去
- 例如桶的原大小4 , 节点的hash 3、7、11、15
get
remove
- 树相关的方法
HashMap 与 HashTable
- HashMap 是线程不安全的,HashTable 线程安全,因为它在 get、put 方法上加了 synchronized 关键字。
- HashMap 和 HashTable 的 hash 值是不一样的,所在的桶的计算方式也不一样。HashMap 的桶是通过 & 运算符来实现 (tab.length - 1) & hash,
- 而 HashTable 是通过取余计算,速度更慢(hash & 0x7FFFFFFF) % tab.length (当 tab.length = 2^n 时,因为 HashMap 的数组长度正好都是 2^n,所以两者是等价的)
- HashTable 的 synchronized 是方法级别的,也就是它是在 put() 方法上加的,这也就是说任何一个 put 操作都会使用同一个锁,而实际上不同索引上的元素之间彼此操作不会受到影响;
- ConcurrentHashMap 相当于是 HashTable 的升级,它也是线程安全的,只有在多个线程操作同一个数组索引的时候才出现锁等待,降低了锁竞争情况
总结
- HashMap是一种散列表,采用(数组 + 链表 + 红黑树)的存储结构;
- HashMap的默认初始容量为16(1«4),默认装载因子为0.75f,容量总是2的n次方;
- HashMap扩容时每次容量变为原来的两倍;
- 当桶的数量小于64时不会进行树化,只会扩容;
- 当桶的数量大于64且单个桶中元素的数量大于8时,对应的桶进行树化;
- 当单个桶中元素数量小于6时,对应的桶进行反树化;
- HashMap是非线程安全的容器;
- HashMap查找添加元素的时间复杂度都为O(1);
Tips
发生 ConcurrentModificationException 时:
- 使用 ConcurrentHashMap 替换掉 HashMap (推荐)
- 使用 synchronized 限制迭代或修改方法
hashmap的实现原理,从负载因子,冲突处理,equals,hashcode一口气讲下来,中间没卡壳儿的。虽然这不是什么太高深的东西,但还是可以感觉得到理论基础特别扎实。
好多工作五六年的人解释不清楚equals和hashcode这两个函数在hashmap中干嘛用的。回答模式一般都是先从理论,原理层面把这个问题讲清楚,然后再从最佳实践方面讲一下不同的应用场景会涉及哪些问题,最后是他做过的项目怎么用的。
数据竞争: put, resize, rehash, fail fast
扩容死循环问题
|
|
- 出现的场景
- 假设容量为4 负载因子0.5, 插入三个节点, 且三个节点的hash值一致, 那么在插入第三个节点时就需要扩容
- 如果有两个线程在执行这个插入操作, 也就是会同时进行扩容, 且线程1执行完
1后被挂起了- 线程2执行完了这个while循环, 完成了扩容, 但是对于线程1来说还需要继续执行
- 且转移节点时采用的是头插法, 于是就容易导致链表出现了环, 那么之后对这个下标的链表进行 get 时, CPU 就满载死循环了
- 并且如果线程2执行完了该方法, 且将自己new的桶覆盖了原有的桶, 线程1才继续执行 还会导致数据丢失
|
|
JDK8 扩容时采用的方式是将一个链表按原有顺序拆分成两个链表 而且采用的是尾插法, 即使是出现了并发问题, 只是重复执行了操作, 不会出现环
栈溢出问题
Flink 中 大量集合进行 union 操作时, 由于 HashMap空间不够而导致的 hashCode hash put 函数递归调用
Author Kuangcp
LastMod 2019-04-16