Protobuf
Contents
💠
💠 2024-11-18 14:31:55
Protobuf
Google开源的序列化框架 全称
Google Protocol Buffers| Github : Protobuf | wikipedia
- 将数据结构用
*.proto文件进行描述, 通过代码生成工具, 生成对应数据结构的 POJO 对象和 Protobuf 用到的方法和属性- 特点:
- 结构化数据存储格式,类似于 XML JSON等
- 高效的编解码性能
- 独立的IDL,语言无关, 平台无关, 扩展性好
- 官方支持 Java C++ Python Objective-C C# JavaScript Ruby
- 数据描述文件和代码生成机制优点:
- 文本化的数据结构描述语言, 可以实现语言和平台无关, 特别适合异构系统间的集成
- 通过标识字段的顺序, 可以实现协议的前向兼容 在不同版本的数据结构进程间进行数据传递
- 自动代码生成, 不需要手工编写同样数据结构的C++和Java版本;
- 方便后续的管理和维护,相比于代码, 结构化的文档更容易管理和维护
- 特点:
- 习惯性规则:
- 命名:
packageName.MessageName.proto
- 命名:
protobuf 只是编解码的工具, 本身不支持处理TCP中读半包、粘包、拆包问题,只是序列化后的二进制流能更方便处理这些问题
参考: Protobuf语言指南
较为详细, 只是版本有点旧
参考: Protobuf3语言指南
proto文件定义
|
|
上面定义了一个消息, 消息具有三个属性, 且行末的注释 经 protoc 编译后都会变成Javadoc注释
message是定义消息的关键字required表示这个字段是必需的, 必须在序列化的时候被赋值。optional代表这个字段是可选的,可以为0个或1个但不能大于1个。repeated则代表此字段可以被重复任意多次包括0次。int32和string是字段的类型。后面是我们定义的字段名。- 等号右边 1,2,3 则是代表每个字段的一个唯一的编号标签,在同一个消息里不可以重复
- 这些编号标签用与在消息二进制格式中标识你的字段,并且消息一旦定义就不能更改
- 需要说明的是标签在1到15范围的采用一个字节进行编码。所以通常将标签1到15用于频繁发生的消息字段
- 编号标签大小的范围是1 到 2的29次幂–1。此外不能使用protobuf系统预留的编号标签(19000 -19999)
数据类型
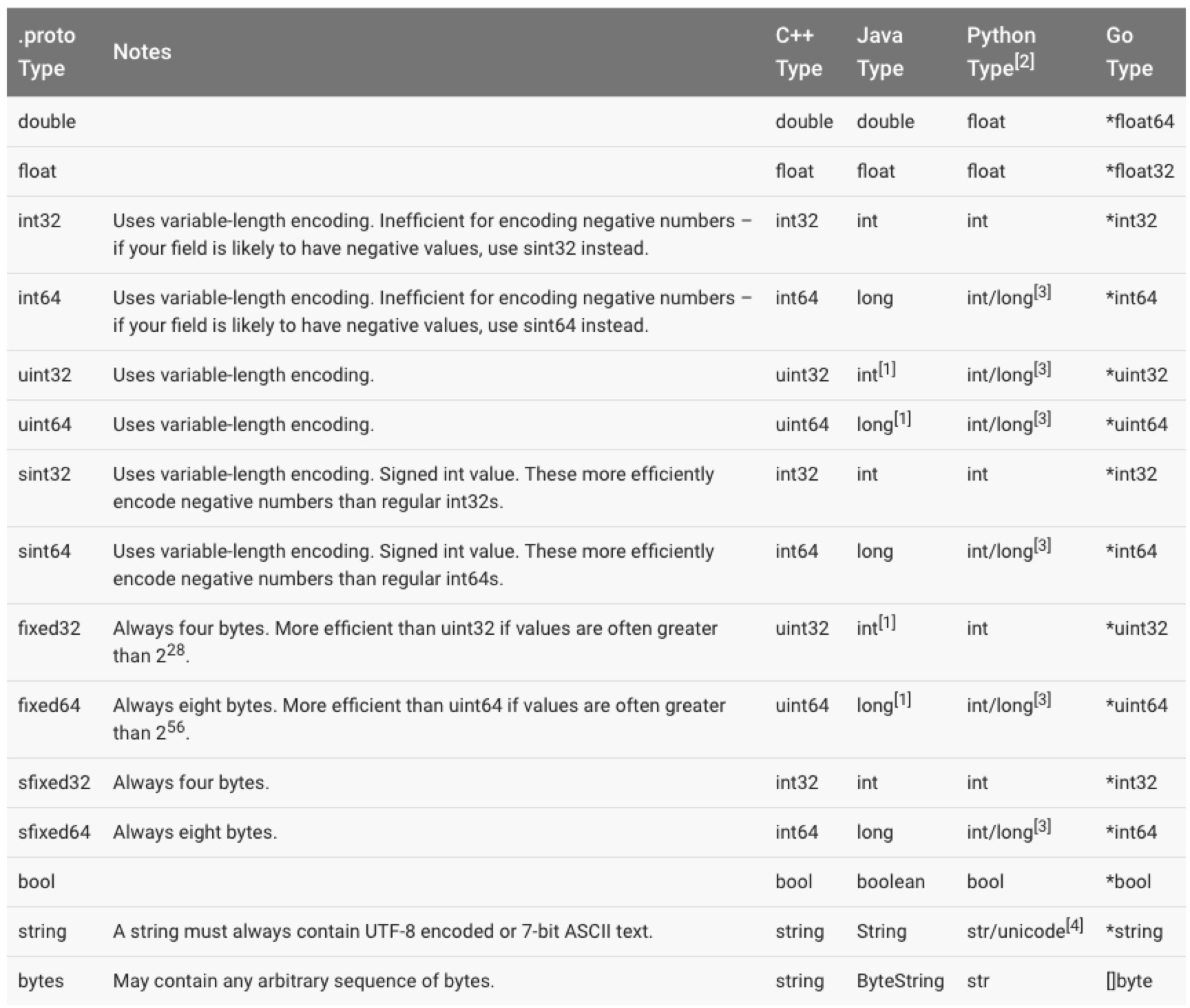
复杂类型
定义了enum枚举类型,嵌套的消息。甚至对原有的消息进行了扩展,也可以对字段设置默认值。添加注释等
|
|
此外reserved关键字主要用于保留相关编号标签,主要是防止在更新proto文件删除了某些字段,而未来的使用者定义新的字段时重新使用了该编号标签。这会引起一些问题在获取老版本的消息时,譬如数据冲突,隐藏的一些bug等。所以一定要用reserved标记这些编号标签以保证不会被使用
当我们需要对消息进行扩展的时候,我们可以用extensions关键字来定义一些编号标签供第三方扩展。这样的好处是不需要修改原来的消息格式。就像上面proto文件,我们用extend关键字来扩展。只要扩展的字段编号标签在extensions定义的范围里。
对于基本数值类型,由于历史原因,不能被protobuf更有效的encode。所以在新的代码中使用packed=true可以更加有效率的encode。注意packed只能用于repeated 数值类型的字段。不能用于string类型的字段。
在消息Other中我们看到定义了一个oneof关键字。这个关键字作用比较有意思。当你设置了oneof里某个成员值时,它会自动清除掉oneof里的其他成员,也就是说同一时刻oneof里只有一个成员有效。这常用于你有许多optional字段时但同一时刻只能使用其中一个,就可以用oneof来加强这种效果。但需要注意的是oneof里的字段不能用required,optional,repeted关键字
- 修改Protobuf文件的建议:
- 不能改变已有的任何编号标签。
- 只能添加optional和repeated的字段。这样旧代码能够解析新的消息,只是那些新添加的字段会被忽略。但是序列化的时候还是会包含哪些新字段。而新代码无论是旧消息还是新消息都可以解析。
- 非required的字段可以被删除,但是编号标签不可以再次被使用,应该把它标记到reserved中去
- 非required可以被转换为扩展字段,只要字段类型和编号标签保持一致
- 相互兼容的类型,可以从一个类型修改为另一个类型,譬如int32的字段可以修改为int64
- 使用上, 因为有多个消息类型, 那么会采用一个数值id作为code, 进行对应 方便沟通
Protobuf3
why remove required and optional
Linux上安装Protobuf
-
下载二进制(推荐)各个版本,平台的 protoc -
编译安装- 下载2.5 并解压
- 进入目录
./configure makemake checksudo make installprotoc --version
注意: ./configure 时, 默认会安装在/usr/local目录下,可以加
--prefix=/usr来指定安装到/usr/lib下
- 如果不加, 上述参数就要执行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib- 当然,可以将这个环境变量的设置加在 .zshrc 或者 .bashrc 里
- 不然就会报错:
protoc: error while loading shared libraries: libprotobuf.so.8: cannot open shared object file: No such file or directory
Java中的使用
实现原理
参考: 图解Protobuf编码
参考: protobuf 编码实现解析(java)
Google Protocol Buffer 的使用和原理C++ 但是原理差不多
Author Kuangcp
LastMod 2019-04-20